it’s honestly both jarring and disheartening that even at this stage of the game the same shabby tricks keep getting trotted out to try to make the abject failures of covid vaccines appear to be victories.
they have slanted data, rigged studies, used mice to stand for people and biomarkers to stand for clinical efficacy. truly, the whole panoply of prevarication has been deployed to try to cover for the basic fact that these products barely worked when they were launched, likely only ever had positive risk reward in extremely high risk people, and given their leaky/non-sterilizing nature were always going to rapidly drive viral escape and viral advantaging as hoskins effect/OAS set in.
this not only inverted efficacy but likely has large negative societal effects overall. i doubt you could make a case for these “vaccines” in even the highest of high risk categories anymore. they’re pretty much all negative net value on risk/reward for pretty much everyone.
and this would seem to be why they are no longer even trying. why seek data when you can simply conjure efficacy by going back to that most egregious of fabulism follies: completely making stuff up?
come now señor cat, surely this is too harsh an indictment!
it certainly seems an impressive set of claims to wave around.
but here’s the thing: it’s not a study at all.
it’s just a model pretending to be data.
it’s literally just self-referential circular assumption bias being passed off as fact by making it sound “sciency”
Rather than modeling population-level effects, the team of researchers from the University of Maryland, York University, and the Yale School of Public Health used a computational model that allowed them to incorporate factors like waning immunity or different age groups’ eligibility for vaccines and boosters into their calculations. Fung noted that adding all of these parameters together creates more statistical uncertainty in the data, meaning that there’s a larger margin for error in the study’s final results. The authors acknowledge this uncertainty by providing “credible intervals” for their calculations — ranges that show, for example, that their estimates for the number of averted deaths would be between 3.1 million and 3.4 million.
what they are basically saying here is that if you make a whole bunch of small assumptions and then multiply them by one another, you get BIG error. that, at least, is honest.
this however, is not:
To calibrate their model, the researchers first made sure it could correctly predict actual case, hospitalization, and death patterns for the December 2020-November 2022 time frame. They then removed the vaccination elements of the model to examine what would have happened without the Covid-19 vaccines.
this is the oldest trap in hindcasting. if you took this claim to any wall st desk or HFT shop, they would be on the floor laughing. it is hilariously easy to build a model full of plug variables or odd inflections/assumptions that fits past data. you just lock in the presumed effect of a couple things you care about and then bend everything else into shape around it.
it is so rare that such a model would then go on to exhibit future predictive value that pretty much no one even bothers trying this sort of approach anymore unless they are either woefully ignorant and about to learn about how expensive lessons in finance can be or they are trying to fleece the rubes.
neither is a moneymaker. (at least not for the rubes)
epidemiology is no different.
excursions into nonsense
“The model incorporates the age-stratified demographics, risk factors, and immunological dynamics of infection and vaccination. We simulated this model to compare the observed pandemic trajectory to a counterfactual scenario without a vaccination program. “
adding vast complexity to a nonsense methodology does not even out into some sort of reasonable average. it just gets you complex nonsense with far greater potential for radical error excursions.
this looks very technically impressive
until you remember all the other models just like this that got trotted out over and over in covid and backfit perfectly and then fell flat on their faces the minute they tried to make forward predictions because (repeat after me): ability to hindcast says NOTHING about ability to forecast.
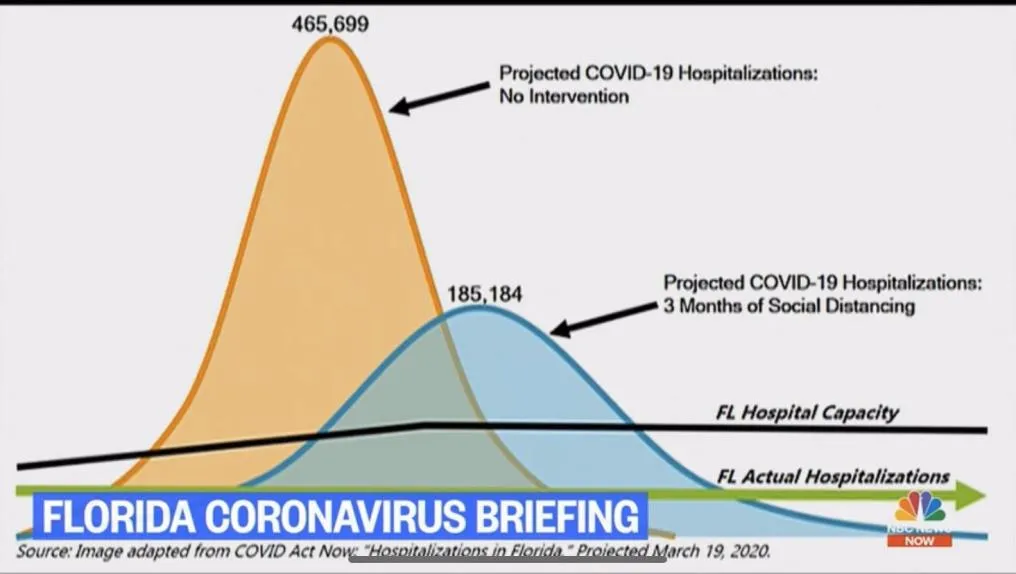
remember this?
this was the same sort of “model” and “variance measure from assumed mitigation.”
the green line (not the black one) was what actually happened.
yeah.
i could pull these all day, but i doubt there’s much point. from SAGE to the UW, we saw this same massive over-estimation trend again and again.
and it’s now being used to validate vaccine effectiveness.
but this is a wholly invalid means to assess such a thing. all you’re really seeing are the assumptions baked into a complex model that we’re not allowed to see or assess or run ourselves.
and it was full of bad assumptions.
they did not even calculate vaccine efficacy or look for curve bending or symmetry violation. they assumed it from exogenous research.
and that was the whole game right there.
we all saw the shenanigans with ignoring immune suppression windows, denominators rigging, population slanting, and 20 other games played on “VE.”
Vaccine efficacies against infection, and symptomatic and severe disease for different vaccine types — for each variant and by time since vaccination — were drawn from published estimates.
just by mathematical necessity, they are clearly assuming VE’s in the 85%+ range. it’s the only way to get to this kind of number given the 70% US vaxx rate (or even 90%+ in high risk) over such a short interval and when around half of US deaths occurred before vaxxes hit even 20% penetration.
(and, obviously, no vaccine works before it is taken)
think about what this means.
let’s assume they are assuming 85% vaccine efficacy (they likely went higher, but this is for illustration). it’s a built in parameter. so if you take it out, deaths spike by 6.7X. this is programmed into the model. it’s not some law of nature. it’s just an assumption based n studies that have long since been invalidated.
When you login first time using a Social Login button, we collect your account public profile information shared by Social Login provider, based on your privacy settings. We also get your email address to automatically create an account for you in our website. Once your account is created, you'll be logged-in to this account.
DisagreeAgree
Connect with
I allow to create an account
When you login first time using a Social Login button, we collect your account public profile information shared by Social Login provider, based on your privacy settings. We also get your email address to automatically create an account for you in our website. Once your account is created, you'll be logged-in to this account.
DisagreeAgree
3 Comments
Inline Feedbacks
View all comments
kitt
1 year ago
Lets compare this computer model and is predictions to all of the climate model predictions, they are batting ZERO.
Deplorable Me
1 year ago
So much of the data was propagandized to make Trump look bad (then ignored when that data made idiot Biden look far, far worse) that we’ll never be able to construct a picture of what COVID did to this nation. All the left cares about is using every possible thing they can to make themselves look better than the next best option, which happens to be far, far better than themselves.
Nan G
1 year ago
Looks like the left assumes all people are a ill-informed about statisitcs and how they can be twisted as they are.
This “research” is pathetic.
I haven’t taken a stat class since the early 1970’s but I can see thru this GIGO.
Good work on the part of the cat for making it so clear.





Lets compare this computer model and is predictions to all of the climate model predictions, they are batting ZERO.
So much of the data was propagandized to make Trump look bad (then ignored when that data made idiot Biden look far, far worse) that we’ll never be able to construct a picture of what COVID did to this nation. All the left cares about is using every possible thing they can to make themselves look better than the next best option, which happens to be far, far better than themselves.
Looks like the left assumes all people are a ill-informed about statisitcs and how they can be twisted as they are.
This “research” is pathetic.
I haven’t taken a stat class since the early 1970’s but I can see thru this GIGO.
Good work on the part of the cat for making it so clear.